Generative AI, the hot word, the buzz word in the tech world right now! Everyone wants to be on board on this ship, but often no one knows where to start off from! Should it be langchain, langgraph, crewAI or API? I have often heard people asking are LLMs and ChatGPT the same thing or different? Often confused themselves with LLM and ChatGPT being two different terms and often considering them the same! Some start with Generative AI, and land up in the depths of machine learning and then find themselves quitting it all!
For quite a bit I thought, if I had to learn generative AI where should I learn from or where should I begin from? Having worked on this field for now around 3 years, I have come to a conclusion, that the first thing one has to know is tokenisation! Not the RAGs, not the Graph RAGs or agentic AI, all these big words are important, but if you were to start, start with tokenisation!
Let’s begin then!
What is tokenisation/tokens?
Tokens are what bits and bytes were for computers. When we started learning computers, we were told, no matter what you enter, a text or an image, it will internally be translated to computers in binary form of 0 and 1. In the world of AI, no matter whether you enter text or image or video or audio, it will first break it down into tokens. The process of translating data into tokens is called tokenisation. The primary reason this matters is that it helps machines understand human language by breaking the data down into bite-sized pieces which are easier to analyze.
Be clear, that it is different from chunking. In chunking the data is split into smaller units, tokenization converts text into the smallest units (words/subwords/characters) that models process and converts text into the smallest units (words/subwords/characters)called tokens that models process.
Why does tokenisation matter?
Efficient tokenisation helps reduce the computing power required for training and inference. It also reduces or increases the overall cost.
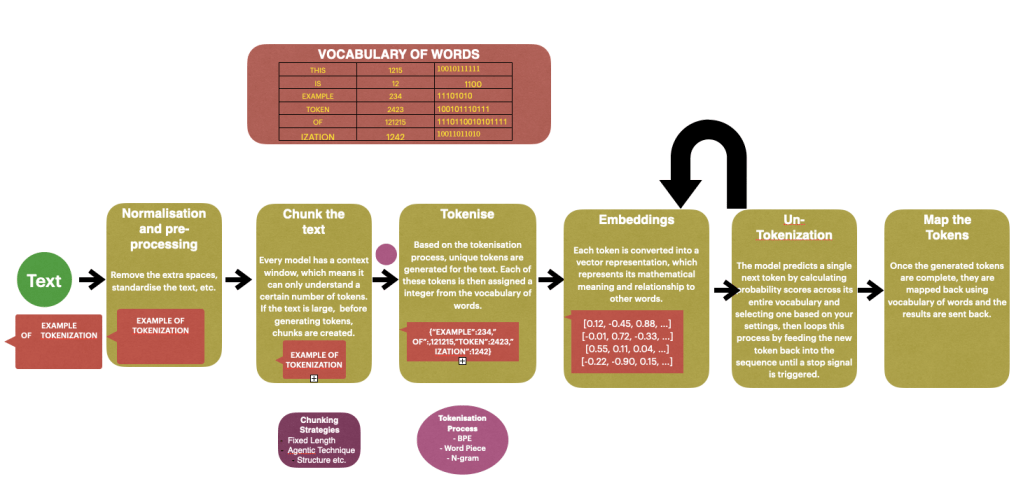
What happens when we prompt an AI?
In simple terms, user enters a prompt, the prompt is split into tokens, these tokens are fed to the model which understands these tokens and generates its response in tokens, the generated tokens are then sent back to the user in user understandable format. We will talk more about it in the next blog . Till then hope this image helps !
Types of Tokenisation
Once we have a data that is within the context of LLM, tokenization happens. Let us understand each of its types –
WORD TOKENIZATION
The text is split based on a defined delimiter. It could be spaces or punctuation or any other delimiter.
- White space tokenization – In this case the text is split by words based on space. So, whenever a space is encountered the text is split into tokens. Example – “Generative AI space is fun!”, tokens created- [‘Generative’,’AI’,’space’,’is’,’fun!’] – Notice here that fun! has ben treated as a new word.
- Problem – Out of Vocabulary Error – Notice here that fun! has been treated different from fun, so even when there is a word fun in the vocabulary the model will not be able to understand it and assign it a value that it does not understand, leading to missing out on the understanding of that token.
- Punctuation based tokenization – This is an addition to the white space based. In this case, the text is split based on space and on punctuation. Example – “There isn’t any other space than Generative AI which is fun currently”, tokens created =[“There”,”isn”, “‘”,”t”,”any”,”other”,”space”,”than”,”Generative “,”AI”,”which”,”is”,”fun”,”currently”]. Had there been a ! mark along with fun in this case, it would have still treated fun separately which removes the error we faced with white space.
- Problem – Because it splits on punctuation, it is difficult for the model to understand that isn’t is actually is not!
- Penn tree bank tokenization – This is the smarter version of punctuation based. It uses a set of linguistic rules to know what belongs together. Example – “U.S.A is the hub of GenAI”, tokens generated [‘U.S.A’,’is’,’the’,’hub’,’of’,’GenAI’]. Notice in this case U.S.A has been treated as a single token, had it been punctuation based tokenization, it would have considered them separately.
- Although, generally better than the other two, it generally fails in domain specific tasks.
You can know more about different tokenization techniques – here
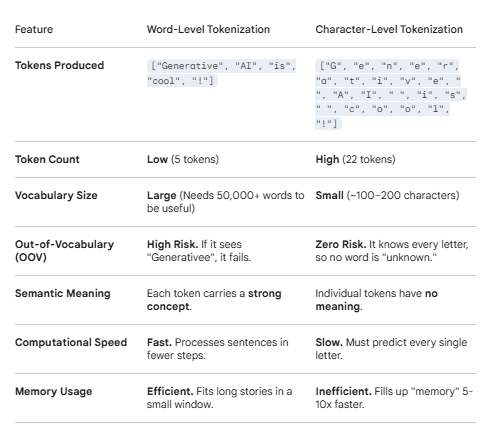
CHARACTER TOKENIZATION
In this method, every character is split and a token is generated. Example – “GenAI is cool”, tokens generated – [‘G’,’e’,’n’,’A’,’I’,’i’,’s’,’c’,’c’,’o’,’o’,’l’]. Spaces are not considered tokens here, all letters or numbers become tokens, and because of this, the vocabulary requirement reduces. For whichever language, only the characters forming this language are considered vocabulary. This technique also helps with typos, so if someone types cooooool, it will still be considered because it is looking at it from character perspective. Cases matter here. So, G and g are considered two different tokens. In this case, usually before tokenization happens, the text is converted to either lower case or upper.
Problems-
- Context Matters – Every LLM can only understand a certain amount of tokens in a go! In case of character tokenization, the number of tokens generated are too huge, considering each character is a token.
- Massive amount of processing power – Since the model has to understand each character, join it and then understand the context, it requires a lot of processing power. For example, in case of word tokenization, generative is a word and a token, in case of character, the model has to go through, g,e,n,e,r,a,t,i,v,e to even get to its context. Because of this, to understand the semantic meaning of the entire text becomes more difficult.
- Training time – Because the number of tokens, or sequences are too high, it takes significantly longer time to train the model.
SUBWORD TOKENIZATION
This technique is the middle point of character tokenisation and word based tokenisation. Frequently used words are kept intact, while rare used words are divided into sub-tokens. This technique is the backbone of the modern LLMs. Let’s look at the three major subword tokenisation techniques –
- BPE – Byte Pair encoding
- Used by GPT models, RoBERTa, and LLaMA, BPE builds its vocabulary from the bottom up.
- CORE CONCEPT – Imagine you are reading a book, and you notice that the letters “t” and “h” appear next to each other constantly. To save space and time, you decide to glue them together into a single block “th”. Later you notice, that “th” is almost always followed by “e”. So, you glue them together into a block “the”. BPE automates the gluing process based on statistical frequency.
- WHAT HAPPENS WHEN A PROMPT IS SENT TO BPE
- Wordpiece
- Used by BERT and DistilBERT
- This is similar to Byte pair encoding, but differs in the way it merges token. It uses a smarter statistical approach rather than just counting what pairs appear most often.
- BPE vs wordpiece
- BPE asks which two tokens appear next to each other the most.
- Wordpiece asks which two tokens create the most unexpected or meaningful combination when put together?
- WHAT HAPPENS WHEN A PROMPT IS SENT TO WORDPIECE
- HOW IS THE VOCABULARY FORMED FOR WORDPIECE
- Unigram
- Used by T5 and ALBERT
- It starts with a massive bloated vocabulary of full words and long substrings, and iteratively prunes away the least useful token until it reaches its target size.
- CORE CONCEPT: Instead of asking, what pieces can be glued together, it asks if I delete this specific token from my vocabulary, how much will it hurt my ability to read and understand the training text. If deleting a token barely matters because the text can be easily spelled out using other pieces, unigram drops it. if deleting a token makes the text incredibly difficult or inefficient to spell, unigram keeps it.
- HOW UNIGRAM TRAINING HAPPENS?
- HOW ARE PROMPTS HANDLED IN UNIGRAM?
- Byte level BPE
- This is an advanced evolution of the standard BPE algorithm.
- Used by GPT-2,GPT-3,GPT-4 to LLaMA and Mistral
- BBPE operates directly on raw binary bytes(0to255)
- This is specially helpful when we are dealing with multi-lingual text.
- Instead of starting with alphabets of thousands of unique characters, BBPE sets its based vocabulary to exactly the 256 possible byte values. Because every single string on the internet can be broken down into these 256 bytes, a BBPE tokeniser can ingest any text in any language, real or imaginary, without ever requiring [UNK] token. In this case, the concept of unknown character completely vanishes.
- Vocabulary Formation in BBPE
- HOW ARE PROMPTS HANDLED IN BBPE?
| Algorithm | Notable Models | The Good (Pros) | The Bad (Cons) |
| BPE (Byte Pair Encoding) | Original GPT, some early translation models | • Data-driven: Efficiently balances vocabulary size and sequence length by merging the most frequent character pairs. • Reduces OOV: Significantly reduces Out-Of-Vocabulary (OOV) tokens compared to word-level tokenization. | • Bloated Base Vocab: If applied to Unicode characters, the base vocabulary must be huge to cover all languages and symbols. • Greedy: Always merges the most frequent pairs, which can sometimes lead to unnatural or suboptimal word splits. |
| BBPE (Byte-Level BPE) | GPT-2, GPT-3, GPT-4, RoBERTa, BART, LLaMA | • Zero OOV: Because the base vocabulary is just 256 bytes, it can represent literally any text, symbol, or emoji in existence without ever outputting an <unk> (unknown) token. • Universal: Excellent for multilingual models and code generation. | • Inefficient for non-Latin text:A single character in Arabic, Chinese, or Hindi might require 3 or 4 bytes. This means text in these languages eats up the model’s context window much faster than English text. |
| WordPiece | BERT, DistilBERT, Electra | • Likelihood-based: Instead of just merging the most frequentpairs like BPE, it merges pairs that maximize the likelihood of the training data. This often results in more linguistically intuitive splits (e.g., catching root words and suffixes). | • Strict OOV handling: If it encounters a character that was completely absent from its training data, the entire word is often replaced with <unk>. • Deterministic: Only provides one way to tokenize a word, missing out on training regularization benefits. |
| Unigram | T5, ALBERT, XLNet, MarianMT | • Probabilistic: Starts with a massive vocabulary and iteratively removes the least useful tokens. • Multiple outputs: It can output multiple valid tokenizations for the same word with different probabilities. This allows for “subword regularization” during training, making models more robust to typos and variations. | • Complex to train:Computationally heavier and more complex to implement than BPE or WordPiece. • Needs a fallback: Doesn’t inherently solve OOV on its own; it relies on a strict base vocabulary and will fail on unseen characters unless paired with a byte-fallback mechanism (often done via SentencePiece).*- |
Happy Learning 🙂

Leave a comment